First Principles of AI Usage — Part 6
Ninety percent of engineering teams now use AI. Only 23% extract meaningful productivity gains from it.
That gap is not a tooling problem. The teams in the 23% are not running better models or allocating larger budgets. They have built a discipline the other 77% have not: they treat AI interaction as a refinement loop, not a one-shot transaction.
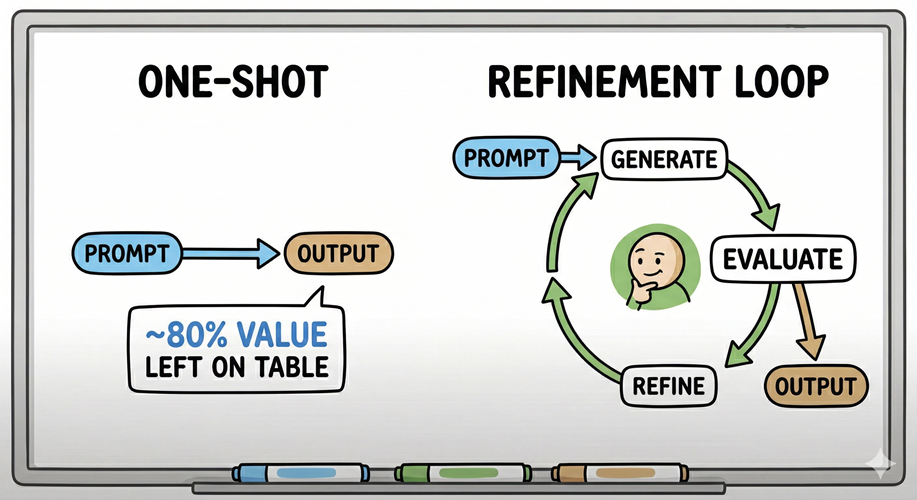
The Failure Mode Is Structural
Prompt-and-accept is the default behavior. Craft the best possible question, receive an output, move on. It feels efficient. It leaves most of the value on the table.
The instinct is understandable. AI produces a coherent, well-structured response on the first pass. It reads like a finished artifact. That fluency is the trap; a well-written output and a correct output are not the same thing, and the first pass is almost never calibrated to your specific context, constraints, or market position.
First pass is always a draft. Treating it as anything else is where teams stall.
The Research Is Unambiguous
In 2023, researchers at Carnegie Mellon published the Self-Refine framework at NeurIPS. The finding: when a model generates an output, receives structured feedback on that output, and refines against that feedback, using the same model for all three roles, performance improves by approximately 20% on average across diverse task types. No additional training. No new data. The same model, operating in a loop.
The mechanics matter here. Self-Refine positions generation as a starting point, not a destination. The model evaluates its own output against explicit criteria, identifies specific weaknesses, and produces a revised version. The cycle repeats until improvement plateaus. First and second iterations yield the largest gains; by the third or fourth cycle, roughly 80% of the achievable improvement has been captured.
The implication for practitioners is direct: one pass captures approximately 80% less value than a structured loop. That is a significant inefficiency.
What This Looks Like at Work
Consider market research; a task most product-oriented engineering leaders, like myself, run regularly when assessing competitive positioning, evaluating feature viability, or scoping a problem space. A single prompt will produce market research. It will also produce generic framing calibrated to an average market, citations that may include your own company’s products as competitors, and analysis that has no awareness of where your organization actually sits in the landscape.
Iterative refinement changes what you get. A first pass surfaces the landscape. A second pass removes irrelevant competitors and tightens the scope to the specific problem space you are assessing. A third pass tunes the framing to your company’s actual market position and eliminates circular references. Each cycle applies a targeted constraint. Each constraint produces a meaningfully different artifact.
The question is not “did the AI provide an answer?” The question is “have I refined the answer to the resolution my decision actually requires?” Those are different questions. Most teams only ask the first one.
Iteration Operates at Two Levels
Refinement is not a uniform operation applied to everything. It works at two distinct levels, and conflating them produces overhead without proportional return.
The first is process-level iteration: each decomposed step in a workflow can be independently refined. You tune the components in isolation. A research step, a synthesis step, a formatting step. Each can be sharpened without touching the others. This is where you tune for quality at the unit level.
The second is output-level iteration: at significant milestones in the workflow, you evaluate the aggregate output against the larger objective and refine it as a whole. Not at every micro-step. At the checkpoints where the accumulated output is visible and the relationship to the original intent can be assessed.
The discipline is knowing which level you are operating on. Low-level iteration tunes components; high-level iteration validates that the components are producing the right emergent output. Both are necessary. They are not the same operation, and applying output-level scrutiny to every atomic step is where refinement becomes friction rather than a feedback loop.
The Trap: Summary of Summaries
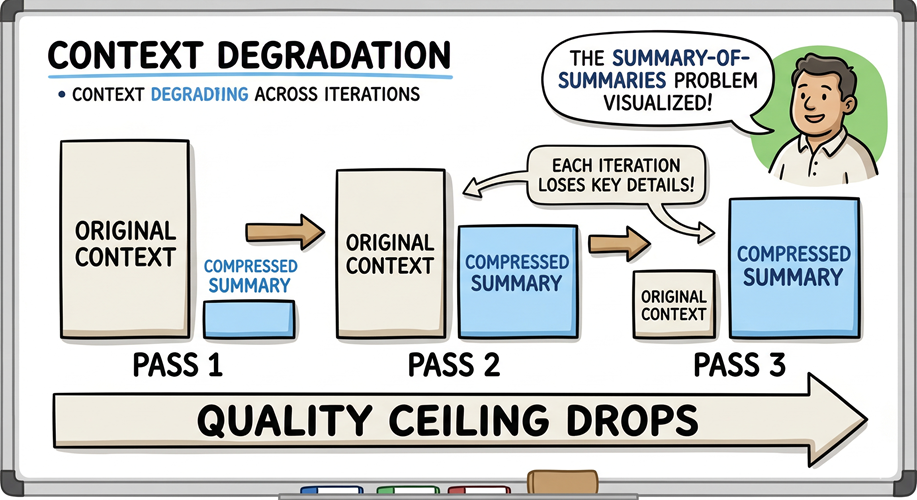
Iterative refinement has a failure mode that is not obvious until you have encountered it.
When each refinement cycle takes only the prior output as its input – no fresh grounding, no reintroduction of the original constraints – the model refines on top of a context window that has already been compressed. Each pass distills the previous pass. Each distillation amplifies the errors present in its input and progressively compresses the nuance of the original source material. This is the summary-of-summaries problem, and it plagues naive refinement loops.
The antidote is Principle 1: context is the product. Refinement cycles must be anchored to the original context; the source material, the constraints, the objective. It cannot be anchored solely to the output of the prior iteration. A model evaluating only its predecessor’s output is not refining the original artifact; it is compounding a summary. The quality ceiling drops with every pass.
Structured refinement means carrying the original context forward. The model needs to evaluate each revised version against the original intent. This is not a limitation of the technology; it is a constraint of how context windows function, and managing it is the thought leader’s responsibility.
The Discipline That Separates the Teams
The 77% of engineering teams not extracting meaningful gains from AI share a common failure: they have not built refinement into their workflow as a structural practice. They prompt once, assess the output, and move on. The 23% have codified the loop; generate, evaluate against explicit criteria, refine with targeted constraints, repeat at the right milestones.
This is not novel thinking. It is what sound engineering has always required: specification, review, revision. AI compresses the generation cycle enough that teams mistake the speed of the first response for completeness. The first answer arrives fast. The assumption that the first answer is the right answer is where the value leaks.
Build the loop. Carry the context. Know which level you are refining at. The teams that have done this are not working with better AI. They are working with AI better.
Leave a Reply