First Principles of AI Usage — Part 2
AI does not know what is true. It knows what is statistically probable.
This distinction is not academic; it is the operational reality every engineering leader must internalize before deploying AI in any workflow that matters. Large language models generate responses by predicting the most probable next token given the context they have been provided. They do not query a database of verified facts. They do not flag uncertainty when they are wrong. They produce confident, fluent, well-structured text regardless of whether the underlying claim is accurate, fabricated, or somewhere in between.
Verification is not a hedge against edge cases. It is the price of admission.
Fluency Bias Is the Real Threat
Hallucination gets most of the attention, and it deserves some. The same prompt can produce different outputs on different runs. Citations can be fabricated with accurate-sounding journal names, plausible author lists, and real-looking URLs that resolve to nothing. Stanford researchers found that citation hallucinations persist even as overall model accuracy improves; the model gets better at sounding right without necessarily getting better at being right.
But hallucination is only half the problem. The deeper risk is fluency bias.
A well-written wrong answer is more dangerous than an obviously broken one. It passes the first read. It sounds authoritative. It gets forwarded to stakeholders, committed to the codebase, or included in the strategic brief before anyone thinks to verify it. The output that is grammatically coherent, structurally plausible, and factually wrong is the one most likely to survive into production. MIT Sloan’s research on AI bias identifies this explicitly: fluency creates a false signal of competence. That is the failure mode to build for; not the output that is obviously broken, but the one that is confidently wrong.
Thought Leader and Thought Partner
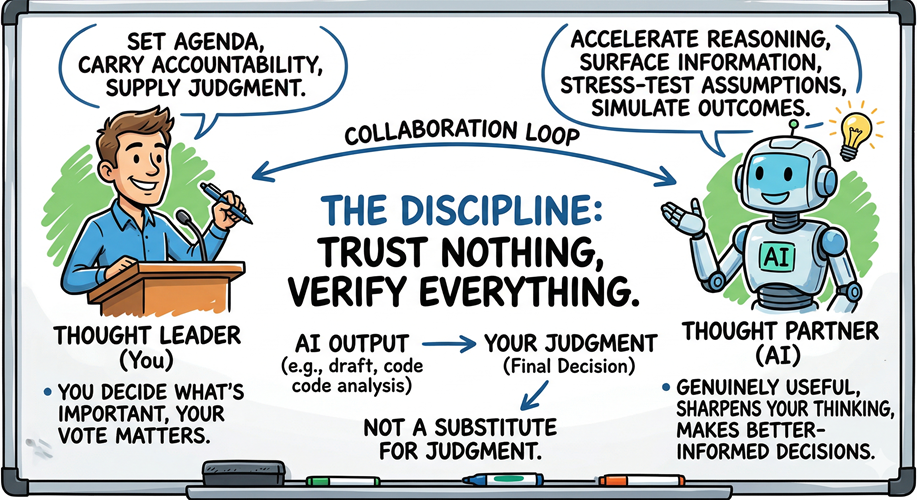
In The AI-Driven Leader, Geoff Woods frames the human-AI relationship with precision: the human is the thought leader; the AI is the thought partner. Part 1 of this series closed on that sentence. This post is about what makes it operationally true.
A thought partner accelerates your reasoning. It surfaces information you did not have, stress-tests assumptions you did not know you were holding, simulates outcomes you would not have had time to think through independently. A thought partner is genuinely useful; it makes your thinking sharper and your decisions better-informed.
But a thought partner does not set the agenda. It does not carry accountability. It does not supply the judgment that separates a good decision from a fast one. The thought leader does all of those things. That is you.
Trust Nothing, Verify Everything is the discipline that keeps those roles correctly assigned. Every AI output that enters your workflow (a draft, a code commit, an analysis, a recommendation) is a starting point for your judgment, not a substitute for it. The moment you treat the model’s output as the conclusion rather than the draft, you have transferred the thought leader role to a system that cannot hold it.
What Verification Looks Like in Practice
Verification is not checking every sentence against a search engine. That eliminates the value AI provides. It is about building a process where AI does the reasoning work and you apply the judgment that only your experience supplies.
In practice, this breaks into three moves.
Shape your thought partner before the work begins. A well-crafted prompt or purpose-built skill dramatically reduces hallucination before verification is ever required. The investment in defining role, constraints, output format, and reasoning steps is effort that does not need to be spent on downstream fact-checking. When the workflow is well-designed, the model works through a reasoning process with you rather than jumping to a conclusion you then have to dismantle. Tighter inputs produce outputs that require less correction; this is context engineering applied to verification.
Use AI to stress-test, not just generate. The most effective verification loop is not human checking AI in isolation; it is AI stress-testing AI, with human judgment applied to the friction points. Ask the model to challenge its own conclusions (and yours), surface the assumptions embedded in a recommendation, simulate the alternative scenario. Adversarial framing reveals weaknesses that a single-pass generation will not. The goal is a reasoning process that surfaces uncertainty rather than concealing it behind confident prose.
Make your own conclusions. Every AI output is input to your judgment. The engineering leader who receives an AI-generated architectural recommendation must evaluate it against constraints the model does not hold: team capability, technical debt, long-term maintainability, organizational priorities. The model can reason about the declared problem; only you can reason about your problem.
The Failure Mode Benchmarks Cannot Catch
The highest-stakes verification failures are not factual errors. They are decisions that are technically correct but architecturally wrong.
In my own Godot projects, AI-assisted development is productive until a code pattern ships that works but violates the structural principles that keep a growing codebase navigable; scenes communicating in ways that create implicit coupling, objects carrying responsibilities they should not hold. Each of those decisions passes compilation. None trigger a test failure. Only a code review catches them; and only if the reviewer carries enough experience to see the downstream implications.
Building coding standards and using an AI agent to verify compliance catches some of these failures. The catches that have most changed how objects communicate in my projects have come from code reviews where the reviewer had sufficient architectural experience to recognize the problem: this works today; in six months it compounds. That kind of judgment does not come from verification tooling. It comes from thought leadership applied at the right moment.
Speed Is Not the Point
The common objection to rigorous verification is efficiency: if verification takes as long as doing it yourself, what is the gain?
The premise is wrong. Speed is not the goal.
The engineers and leaders who build the most impact with AI will not be the ones who complete tasks faster. They will be the ones who reach a level of quality they would not have achieved otherwise; without AI, they would not have invested the time to get there. AI does not accelerate a task you were already going to do at full quality. It improves the work you would have settled for doing at a lower standard, or skipped entirely.
Fully investing your judgment in every AI-assisted output: shaping the context, stress-testing the reasoning, applying your experience to the conclusion. That produces work that is qualitatively better. Each hour of deliberate, AI-augmented thinking produces more impact, not because you moved faster, but because the ceiling on what you can produce in that hour is now higher. The question to ask is not “did this save me time?” It is “would I have produced this without AI?” In most cases, the honest answer is no.
Verification is not overhead on that investment. It is where the value is captured.
The Underlying Principle
AI outputs are probabilistic. Your judgment is not optional.
Shape the thought partner before the work begins. Stress-test the reasoning rather than accepting the first draft. Apply your experience where benchmarks cannot reach. Make your own conclusions and own them fully.
Trust nothing. Verify everything.
References
- The AI-Driven Leader — Geoff Woods
- MIT Sloan EdTech — AI Hallucinations and Bias
- Frontiers in AI — Survey of Hallucinations in LLMs
- Stanford — Hallucination-Free? RAG Legal Hallucinations
Next in the series: Principle 3 — You Own the Output.
Leave a Reply