Your team is shipping faster than ever. The question is whether they understand what they shipped.
Comprehension debt is the growing gap between code volume and genuine developer understanding. It accumulates silently: CI passes, velocity metrics climb, sprint commitments land on time. The debt surfaces only when something breaks and the team discovers that nobody can explain, debug, or safely modify the code they delivered last quarter. Multiple independent studies between 2024 and 2026 now quantify this phenomenon. The evidence is no longer anecdotal.
The Evidence at a Glance
| Study | Scale | Key Finding |
|---|---|---|
| Anthropic RCT (2026) | N=52 junior devs | AI users scored 50% vs. 67% on comprehension (Cohen’s d=0.738, p=0.01) |
| Comprehension-Performance Gap (arXiv 2511.02922) | N=18 grad students | Copilot raised test pass rates with zero improvement in comprehension |
| Debt Behind the AI Boom (arXiv 2603.28592) | 304K AI commits, 6,275 repos | 24.2% of AI-introduced issues survive to latest revision; security issues introduced at 2:1 ratio vs. fixed |
| GitClear (2025) | 211M changed lines, 2020-2024 | Code duplication up 8x; refactoring collapsed from 25% to <10% of changes |
| Stack Overflow (2026) | Industry survey | 76% of devs admit generating code they don’t fully understand |
| LinearB (2026) + Google DORA (2024) | Industry benchmarks | End-to-end delivery 19% slower; 7.2% stability decrease per 25% AI usage increase |
These numbers tell a consistent story. AI coding tools accelerate functional output while degrading the comprehension that makes that output maintainable. The gap between “it works” and “we understand it” is widening across the industry.
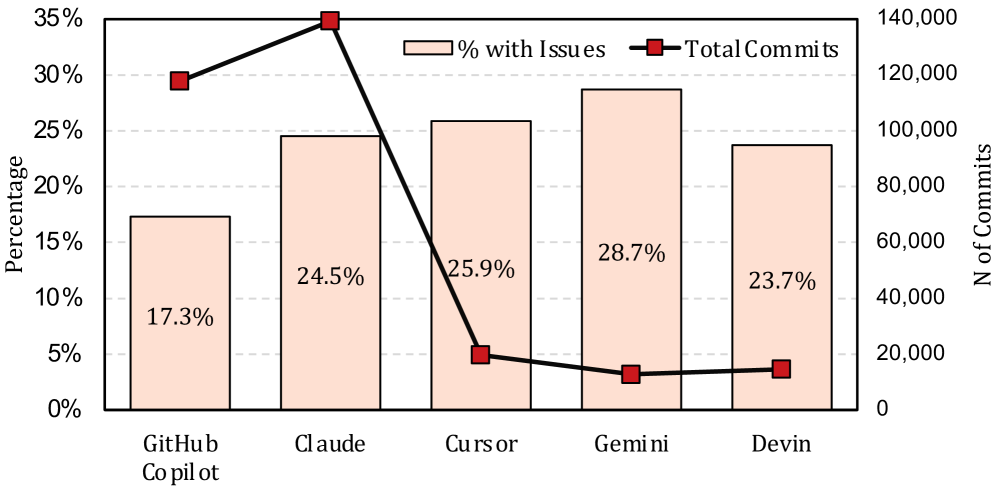
Chart: Li et al., Debt Behind the AI Boom (2026). Issue rates across 304,362 AI-authored commits from 6,275 repositories.
Two findings from this body of evidence deserve particular attention: the mechanism that makes the debt invisible, and the practice that disappears first when it takes hold.
The Broken Feedback Loop
Code review was the knowledge distribution mechanism.
Addy Osmani’s analysis of comprehension debt, identifies the structural failure at the center of the problem. For decades, code review served a dual purpose: quality gate and learning channel. Reviewers built understanding of the codebase by reading changes in detail. Authors clarified their thinking by explaining decisions to reviewers. The friction of that exchange was load-bearing; it forced comprehension to propagate across the team.
Of course, this is on top of the learning that occurred naturally through hand coding the work in the first place, as well.
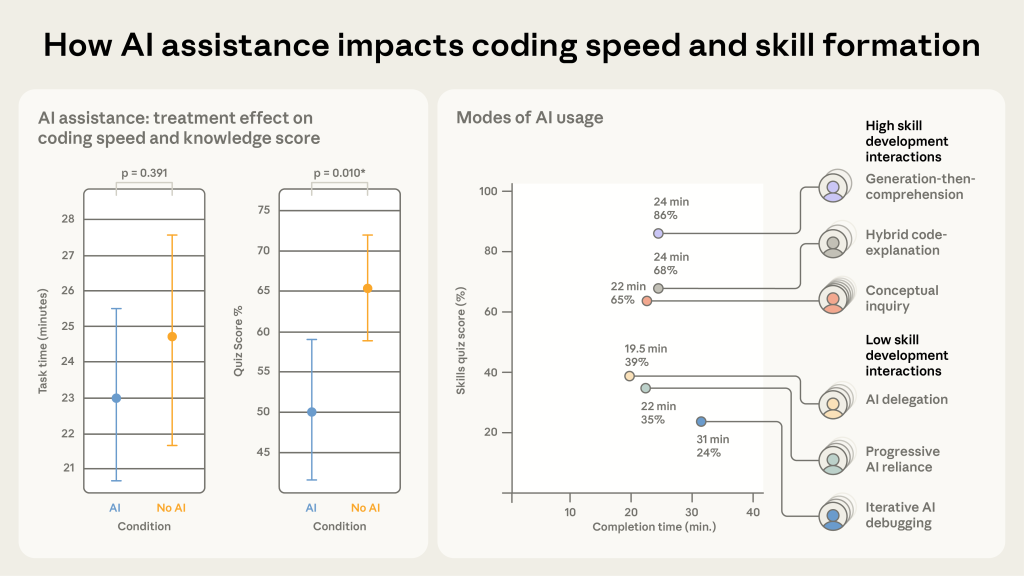
Chart: Anthropic, AI Assistance and Coding Skill Formation (2026). Comprehension quiz scores: AI-assisted (50%) vs. hand-coding control (67%).
AI breaks this loop by collapsing the cost of generating code without collapsing the cost of understanding it. A developer can produce a pull request in minutes that would take a reviewer hours to genuinely evaluate. The asymmetry creates a predictable failure mode: reviewers approve code they have not fully understood, because the volume exceeds their capacity to keep pace.
The insidious part is that traditional quality signals remain green. Tests pass, because the AI-generated code satisfies the specifications that were provided. But as Osmani observes, you cannot write a test for behavior you have not thought to specify. The unanticipated failure modes, the edge cases nobody modeled, the architectural assumptions buried three layers deep; these survive code review and CI/CD entirely. They surface in production, during an incident, at 2 AM.
This carries a regulatory dimension that engineering leaders cannot afford to ignore. “The AI wrote it and we didn’t fully review it” will not survive post-incident scrutiny in healthcare, finance, or government. Accountability does not transfer to the model.
When Refactoring Disappears
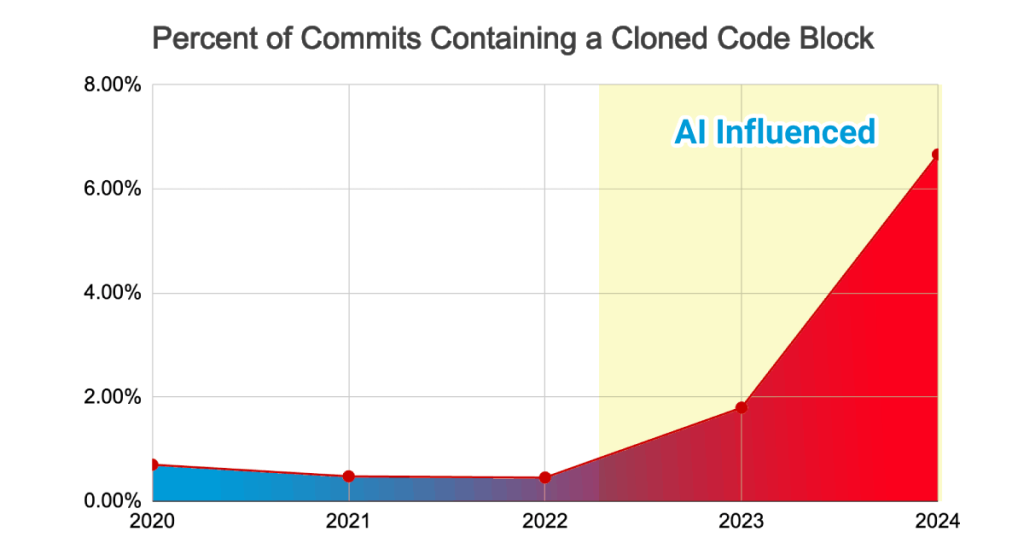
Chart: GitClear, 2025 AI Code Quality Report. Duplicate code block prevalence across 211M changed lines, 2020-2024.
GitClear’s analysis of 211 million changed lines between 2020 and 2024 documents a trend that should alarm any engineering leader tracking codebase health.
| Metric | 2020-2021 | 2024 | Change |
|---|---|---|---|
| Code cloning (copy/paste) | 8.3% of changes | 12.3% | ~8x increase in clone frequency |
| Code churn (revised within 2 weeks) | 3.1% | 5.7% | +84% |
| Refactoring share of changed lines | 25% | <10% | Projected 3% by 2025 |
The refactoring collapse is the most telling signal in the dataset. Developers who do not understand code do not refactor it. They work around it. They duplicate instead of consolidate, extend instead of restructure, and add conditional branches instead of redesigning the abstraction. Each workaround increases the surface area of code that the next developer must comprehend, compounding the debt with every sprint.
There is a paradox here worth naming. AI actually makes refactoring mechanically easier. An engineer with strong comprehension of the current architecture and a clear vision of the target state can direct AI to execute structural changes that would have taken days in hours. Refactoring becomes more attainable when the human understands the system.
But comprehension debt inverts this equation. As understanding erodes, the prerequisite for effective refactoring vanishes. The tool that could accelerate structural improvement instead accelerates structural decay, because the engineer directing it lacks the mental model to guide it well. The AI runs fast. It runs in the direction the engineer points it. If the engineer cannot see the terrain, speed is not an asset.
There is a second-order effect that complicates even the optimistic case. When teams do execute large AI-assisted refactors successfully, those changes shift the ground beneath every other engineer’s existing mental model of the codebase. Code that was understood yesterday now behaves differently. In a pre-AI environment, refactors were small and infrequent enough for teams to absorb incrementally. AI-assisted refactors can be sweeping enough to outpace the team’s capacity to update their understanding. The same capability that enables better refactoring can destabilize the comprehension it depends on.
What Works: Building Comprehension Into the Workflow
Problems are easy to catalog. Solutions are harder to find, and harder still to implement. The evidence for interventions is younger than the evidence for the problem itself, but the strongest remedy already has randomized controlled trial data behind it.
Explanation Gates: The Strongest Evidence
The VibeCheck study (arXiv 2602.20206, N=78, between-subjects RCT) tested a direct countermeasure: an IDE plugin that intercepts AI-generated code insertions and requires the developer to produce a causal explanation before accepting them. An LLM judge evaluates each explanation against the SOLO taxonomy, a learning-depth rubric that distinguishes vague restatement from genuine causal understanding. Restatements are rejected. Relational, causal explanations pass.
The results reframe the conversation:
| Group | Task Completion | Bug Repair Success |
|---|---|---|
| Manual coding (no AI) | 65.2% | 69.2% |
| Unrestricted AI | 92.4% | 23.1% |
| Scaffolded AI (VibeCheck) | 89.1% | 61.5% |
Unrestricted AI use cratered bug repair competence to 23.1%, less than a third of the manual baseline. The explanation gate recovered it to 61.5%, within striking distance of manual coding, while preserving 89.1% task completion. The cost was approximately 14 extra minutes per session. The researchers quantified the gain as reducing epistemic debt from 69.3 points to 27.6 points.
The human response data is equally instructive. 72% of participants called the gate “annoying.” 64% of those who succeeded at the repair task credited it as essential to finding the bug. Friction was the feature.
This finding carries a leadership implication that extends beyond tooling. Simply mandating more rigorous code reviews will produce the outcome it has always produced in teams that do not value comprehension: rubber stamps and failed enforcement. The explanation gate works not because it adds a bureaucratic checkpoint, but because it forces encoding at the moment of acceptance, before the developer has moved on to the next task.
The challenge for engineering leaders is creating an environment where comprehension is rewarded, not just required. Engineers need to feel the positive value of the friction, not just its weight. Teams that celebrate deep understanding of their systems, that treat the ability to explain a module without referencing AI as a genuine technical competency, will sustain these practices voluntarily. Teams that frame explanation gates as compliance overhead will game them the same way they game perfunctory code reviews today.
The mechanism is also fully automatable. The LLM-as-judge approach requires no human reviewers to operate, which removes the scalability objection before it arises. The VibeCheck researchers further propose adaptive friction fading as a future direction: progressively reducing gate frequency as a developer demonstrates mastery of a component, concentrating friction where comprehension risk is highest.
The Consultant Stance (Thought Partnership)
The Anthropic RCT revealed that interaction style predicted comprehension outcomes more reliably than AI usage itself. High-scoring participants averaged 4.2 explanatory follow-up prompts per session versus 0.4 for low-scorers. They treated AI as a consultant to interrogate, not a contractor to accept from. “Why did you use this approach?” and “What happens if this input is null?” are the questions that separate comprehension-preserving AI use from comprehension-destroying AI use.
This intervention is trainable and costless. No tooling required. Teams can codify it as a behavioral norm: for every significant AI-generated block, ask at least one conceptual follow-up before accepting.
The Broader Toolkit
| Intervention | Mechanism | Readiness |
|---|---|---|
| Spec-Driven Development | Forces design articulation before AI generates code | Tools available (GitHub spec-kit, JetBrains Junie) |
| Structured PR contracts | Surfaces comprehension gaps pre-merge via required intent and risk fields | Process only; Osmani’s four-field template |
| TDD + collective ownership | Sets a behavioral specification floor; distributes understanding across team | Established practice |
| Architectural Decision Records | Institutional memory for why the system is shaped as it is | Low overhead; AI-assistable |
| Comprehension reconstruction sessions | Team members explain accepted modules without AI access | Zero cost; untested empirically |
No single intervention eliminates comprehension debt. The highest-leverage combination pairs an explanation gate at the point of acceptance with a consultant prompting norm during generation and organizational practices that distribute understanding rather than siloing it.
The Structural Challenge
Comprehension debt is not a tooling problem. It is a feedback loop problem.
AI accelerates code generation. Code review, the historical mechanism for distributing understanding, cannot keep pace with the volume. Developers accept code they do not fully understand. That acceptance degrades their ability to refactor, debug, and extend the system. The degradation produces more workarounds, more duplication, and more surface area that the next developer will not understand either. The loop feeds itself.
The teams that break this cycle will treat comprehension as a first-class engineering outcome, measured and rewarded alongside velocity and availability. The tools and practices to do this exist today. The question is whether engineering leaders will deploy them before the debt compounds into something more expensive than the productivity gains that created it.
Go and implement one of the tools from the Broader Toolkit section. I’d suggest starting with Spec-Driven Development and Architectural Decision Records.
Leave a Reply